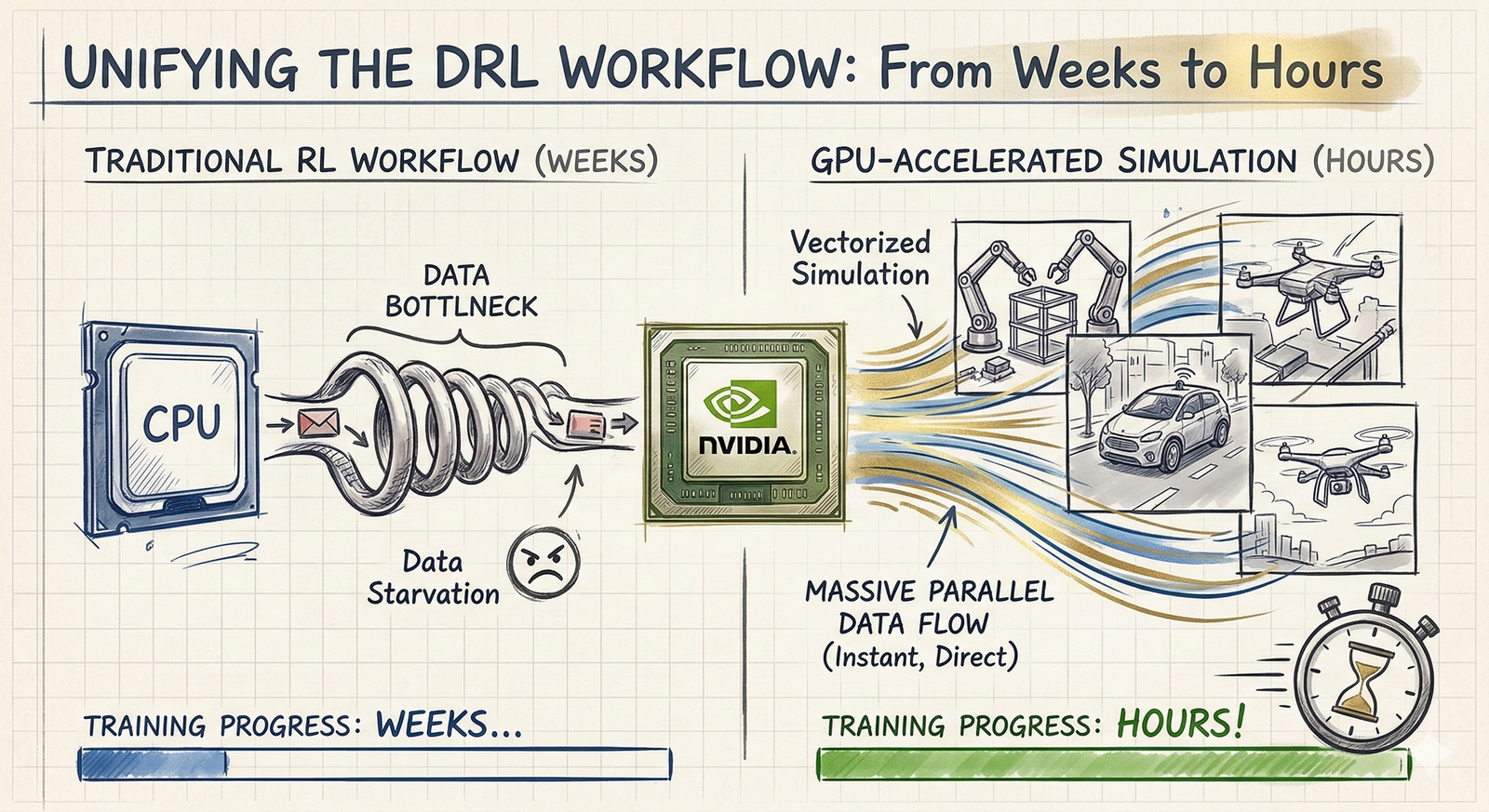
Deep reinforcement Learning (DRL) is the magic behind some of the coolest AI out there, from bots that beat professional gamers (like DeepMind’s AlphaStar mastering StarCraft II or AlphaGo) to robots that can do backflips (such as the Unitree humanoid). But there is a huge catch: these systems learn by pure trial and error. To get smart, an AI needs to practice millions (sometimes billions) of times in a virtual world.
For a long time, we had a major traffic jam. The AI’s brain ran on super-fast GPUs, but the virtual world it practiced in was stuck on much slower CPUs. Moving data back and forth between them wasted tons of time. In the last few years, we’ve been finally moving those virtual worlds directly onto the GPU. This is completely changing the game, turning what used to be weeks of agonizing waiting into just a few hours of work.
As someone who builds these DRL systems every day, I’ve seen firsthand just how much this shift changes everything. It is a total lifesaver. I want to share what I’ve learned to help both newcomers and veterans, especially those still stuck doing things the slow, old-school academic way, navigate this awesome new upgrade and start training their agents faster.
The classic way and the CPU-GPU bottleneck
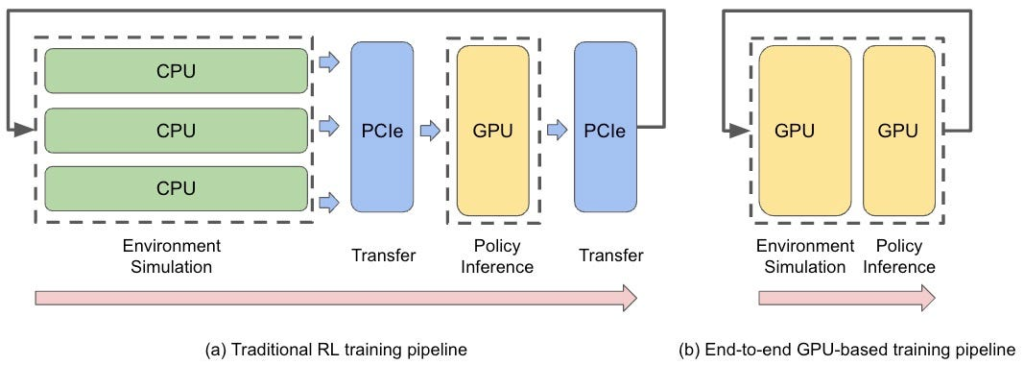
In the standard DRL loop, your agent (usually a neural network) decides on an action. The environment takes that action, updates the physical state, and hands back the new state and a reward. This loop repeats until the agent gathers enough samples to update its policy. Traditionally, the environment runs on the CPU, while the agent’s brain sits on the GPU, since the neural network training is optimized for GPU hardware.
Here is the problem: every single loop triggers two PCIe transfers. Both processors end up sitting idle, just waiting for data to travel back and forth. Modern GPUs are designed to process massive batches of data concurrently, but this traditional setup limits your throughput to the number of physical cores on your CPU. Since you rarely have more than 24 or 64 cores, you are effectively starving your GPU of data. This bottleneck wastes computation, wastes time, and forces you to settle for fewer samples per update, which ultimately hurts your agent’s performance.
The Paradigm Shift: Moving Physics to the GPU
When you move the entire simulation to the GPU, those PCIe waiting times disappear entirely. But the real magic happens through vectorization. Because GPUs are built for thousands of concurrent operations, you can clone your environment thousands of times and run them all in parallel. You are essentially getting thousands of samples for the exact same time cost of one.
This paradigm shift causes training times to drop significantly. What used to require a massive compute cluster running for weeks can now be knocked out on a single high-end workstation in an afternoon.
Low Hanging Fruits of GPU-Accelerated Simulation
Hyperparameter tuning: Modern DRL algorithms are notoriously sensitive to hyperparameters, a frustrating reality famously documented in the milestone paper Deep Reinforcement Learning that Matters. When training takes weeks, proper hyperparameter optimization (HPO) is practically impossible. By shrinking training times to minutes or hours, extensive HPO becomes viable again. This single change is often the difference between a failed project and a breakthrough.
More stable training, making for more sample efficiency: The industry standard algorithm, Proximal Policy Optimization (PPO), thrives on stability and low variance gradients. As demonstrated by massive projects like OpenAI Five, pumping thousands of parallel environments through the GPU yields massive batch sizes. This drastically reduces gradient noise and keeps the training curve smooth and predictable.
Highly dimensional tasks: Supervised learning taught us that larger input spaces cause training instability if batch sizes are too small. Foundational research in visual DRL, like the CURL paper, confirms this is a nightmare when training visual policies, robots with crazy degrees of freedom, swarms, or autonomous driving agents using HD maps.
If your batch size drops below 256 for a visual policy, the agent might never learn. GPU acceleration provides the amount of diverse data required to make these complex tasks mathematically stable.
Better exploration in sparse reward feedback environments: In sparse reward environments, finding the goal is like finding a needle in a haystack. Deploying thousands of parallel agents gives you massive coverage of the state space. Research breakthroughs in exploration, such as Go-Explore, show that massive scale drastically increases the odds that at least one agent stumbles upon that rare, high reward state to unblock the entire training process.
Dynamics Sim to Real Transfer: In complex robotics tasks, you do not simply train on one single static environment. You train across a distribution of environments, applying Domain Randomization to parameters like joint mass or friction. As famously proven by OpenAI’s robotic hand solving a Rubik’s Cube, running thousands of environments simultaneously means your agent experiences a massive chunk of this distribution in every single update step. This prevents the neural network from biasing or over fitting to just a handful of randomized variations.
Massive hardware scaling on a budget: Even without building a massive server farm, keeping everything on the GPU gives you significantly more bang for your buck. When you look at the raw metric of Samples Per Second (SPS) relative to hardware price, a single high-end GPU completely outclasses traditional CPU clusters. You get explosive simulation throughput without the astronomical hardware costs; and if one single GPU doesn’t do the trick, the scale that extra GPUs bring is incomparably higher than the scale of the traditional way brings with the same money investment.
The Leading Players: Fully in-GPU
Since we already know that keeping your pipeline on the GPU is non-negotiable, let’s look at the engines actually making it happen:
- NVIDIA Isaac Gym / Isaac Lab: The undisputed industry standard for robotics right now. It handles physics and rendering natively on the GPU. You should also keep an eye on NVIDIA Warp, a newer built-in Python framework that compiles your simulation code directly into incredibly fast GPU kernels.
- Madrona Framework: It is a newer game engine built specifically for high-throughput RL environments. The documentation is still a bit sparse, but under the hood, it is incredibly flexible.
- Google Brax: Written entirely in JAX, Brax’s superpower is that it is differentiable. Instead of just guessing and checking, your algorithms can compute exact analytic policy gradients straight through the physics dynamics.
- MuJoCo (DeepMind): A classic engine known for strict biomechanical accuracy that simply had to evolve to keep up. DeepMind recently brought it into the JAX ecosystem with MJX, successfully marrying its famous high-fidelity physics with massive hardware acceleration.
- Genesis: The ambitious newcomer. It is a universal physics engine built from scratch for generative AI and RL. Its goal is to simulate everything from rigid robots to squishy materials and fluids, all within one unified GPU architecture.
- Special Mention: PufferLib Even though it doesn’t run strictly on the GPU, PufferLib deserves a shoutout. It tackles the speed problem from the other side by aggressively optimizing CPU operations for traditional Gym environments, which is a lifesaver when GPU simulation just isn’t an option.
The Missing Link: Fully In-GPU RL Libraries
So, you have a blazing-fast GPU simulator. Great. But if you hook it up to a traditional, CPU-first RL framework, you’ve essentially built a racecar and parked it in traffic.
The fix is simple in theory, but tough in practice: the data can never leave the card. In a fully in-GPU pipeline, the environment, the experience replay buffer, the action selection, and the neural network gradient updates all live strictly within the GPU’s VRAM.
Key Libraries to Know
To actually pull off this end-to-end pipeline, you need specialized libraries:
- SKRL: The versatile plug-and-play option and my all times favourite. It supports PyTorch, JAX and Wrap and is designed specifically to interface easily with modern engines like Omniverse and Brax.
- rl_games: Highly optimized, battle-tested for handling massive batches of parallel environments, and serves as the standard companion for NVIDIA’s Isaac Gym. It has, however, less modularity and algorithm diversity than SKRL.
- PureJaxRL: A pure JAX implementation that JIT (Just-In-Time) compiles your entire training loop. By completely cutting out CPU-GPU transfers, it can easily run 1000x faster than a standard SB3 setup.
Conclusion
Marrying a GPU simulator with an in-GPU RL library isn’t just a nice performance boost; it fundamentally rewrites the engineering timeline. By eliminating the hardware bottlenecks of the past, we are entering an era where iteration happens in minutes rather than days.
As these tools mature, the headache of training DRL policies and deploying them to physical hardware, is going to shrink drastically. This is the exact what we need to fast-track the deployment of advanced autonomous systems and general-purpose robots.